
上传数据时识别ID更完整
在上传数据时,IPA能够通过辨识同一个分子不同的ID命名规则来提高数据集上传过程中“mapping”的成功率(能够提高识别ID的个数)。 一个分子能够提供5个命名规则IPA将从左到右辨识,并在成功映射ID时停止(对于该行)。
本次更新的对于识别代谢产物或化合物ID的尤其有价值。图1显示了上传过程中的一个数据集,其中包含代谢物的四列不同命名规则的ID,能够映射的行比单独使用任何一种命名规则的时候要多。
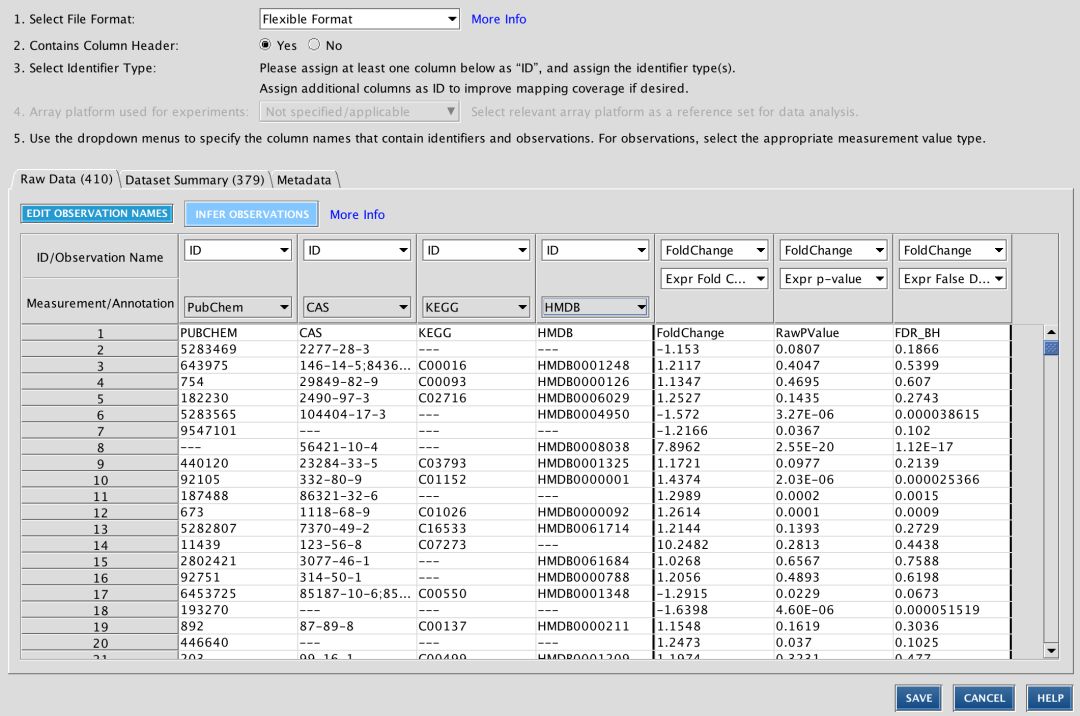
图1:在上传过程中能提供多个命名方式的ID列以增加映射覆盖率。此数据集有四列不同命名规则的ID提供映射。每选择一个命名规则,Dataset Summary就会自动更新能识别的分子数。在本例中,如果只使用HMDB命名规则只能映射344个化合物(行);但当所有ID列(PubChem,CAS,KEGG和HMDB)一起使用时,IPA从左到右扫描,能够映射379个化合物(行)。
使用Benjamini-Hochberg统计数据提高统计严格性
IPA上游调控因子和因果网络分析中引入了Benjamini Hochberg(B-H)校正p值,增加了核心分析中这些结果的统计严格性。B-H p值为多次测试进行纠正——事实上,运行的统计测试越多,观察到假阳性结果的机会就越大。图2显示了核心分析中的上游调节因子选项卡新的B-H列。请注意,这些新的p值不会出现在本次更新之前(2019.3.31)运行的任何分析中。如果需要查看这一统计值,需在本次更新后再重新运行一次核心分析才能查看。
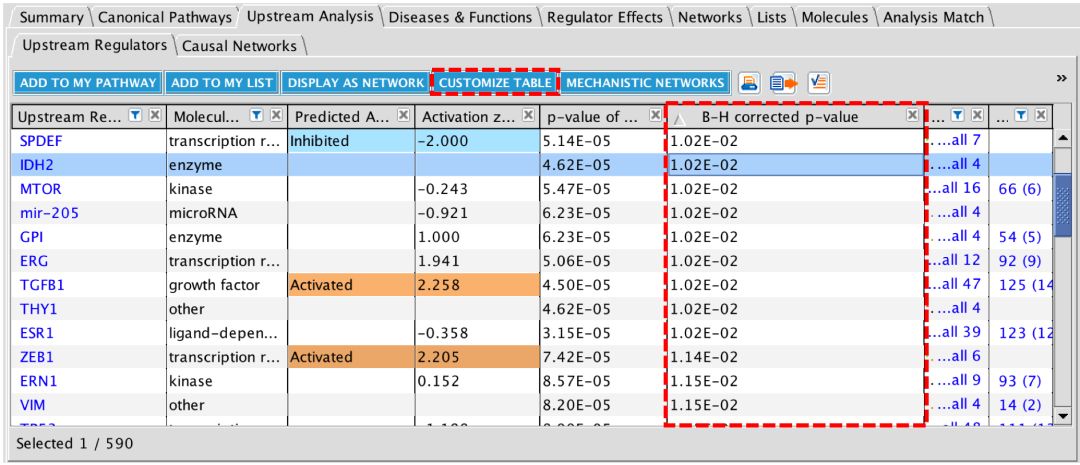
图2:本次更新后,上游调节因子选项卡有一个可选的“B-H校正p值列”。默认情况下不显示该列,必须单击“自定义表”按钮,然后勾选“B-H更正的P值”复选框以显示该列。在本例中,B-H统计获得的B-H p值显著性约为0.01,而标准p值的显著性要多3个数量级。
在IPA中,B-H p值可用于经典通路和疾病和功能分析。如今可以在“疾病和功能”选项卡中选择“B-H”列,如下所示:
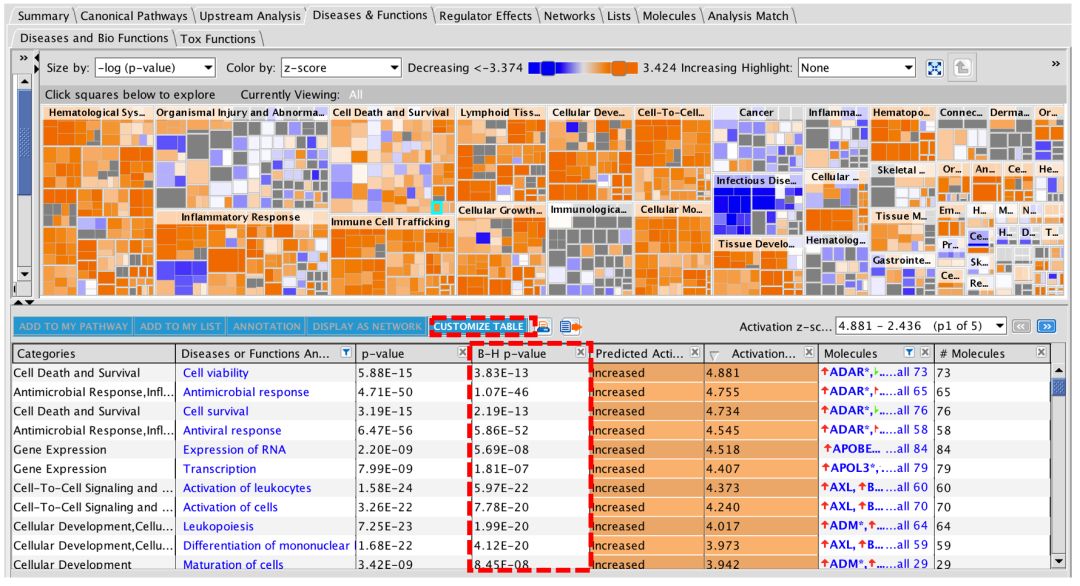
图3:疾病和功能选项卡现在在表中有一个可选的“B-H校正p值列”。默认情况下不显示该列,必须单击“自定义表”按钮,然后勾选“B-H p值”复选框以显示该列。
疾病和功能热图可以用B-H校正后的P值来显示。矩形可以通过B-H p值的-log来着色和/或调整大小,如图4所示。
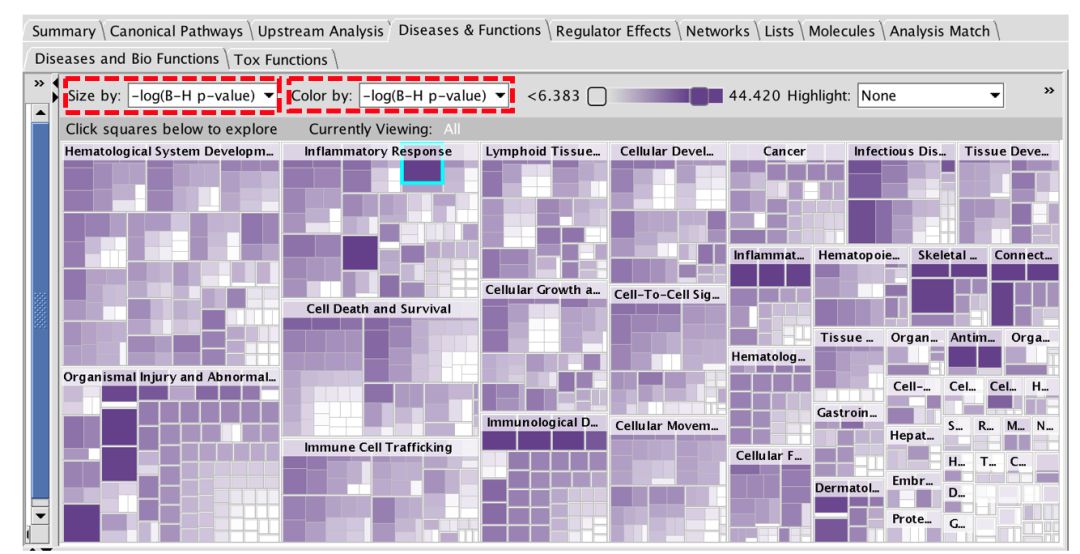
图4:疾病和功能热图可以使用B-H校正后的p值进行可视化。使用菜单(红色虚线框)按B-H p值的-log对热图进行着色和/或调整大小。
本次更新后,Comparison Analysis和 Analysis Match功能也将提供B-H统计信息。
轻松获得视频教程
IPA中的“帮助”菜单现在提供视频教程的快速链接,帮助您开始学习如何使用IPA。主题包括如何格式化和上载数据、如何分析数据以及如何计算IPA中的p值:
图5:IPA帮助菜单中的新视频教程链接。该链接将指向一个新的帮助门户页面,其中包含一组视频以帮助您使用IPA。


