
在浩瀚的化学空间中,类药分子的可能数量预估高达10⁶⁰个!基于现代物理学与机器学习等技术手段,科研人员得以高效地探索这片近乎无限的化学空间。支撑这一技术路径的核心环节是虚拟筛选:药物研发人员会从海量小分子化合物库中,筛选出最有可能与特定蛋白靶点相结合的配体化合物,这类候选分子被称为“苗头化合物”(hit)。
构建高质量的配体库,是探索化学空间、发现新型苗头化合物的必备前提。尽管目前已存在覆盖面广的通用型化合物库,但针对特定筛选项目的目标与需求定制专属配体库,往往能取得更优的研发成效。这种量身定制的策略不仅能最大化筛选结果的价值,还能显著缩短项目的研发周期。
一、 配体库设计的核心原则
设计配体库需要经过严谨的化合物筛选与过滤流程,以便提升库内化合物的相关性与整体质量。一个高质量的配体库需满足以下:
1. 提升虚拟筛选成功率
优质的配体库能够提高发现初始苗头化合物的概率,即便这些化合物的活性强度处于中等水平。这些苗头化合物可作为后续结构优化的起点,在研发的后期阶段,其活性及其他理化性质将得到进一步提升。
2. 确保合成可行性
筛选得到的苗头化合物最好是可直接购买的,或具备化学合成的可行性。明确虚拟化合物的合成边界至关重要,这能有效规避因化合物无法合成而导致的高昂研发损失。例如,某个化合物在计算模拟筛选中可能表现亮眼,但必须确认它是否能够在实验室中被实际合成出来。
3. 优先考量类药性与预测性质
在研发早期就剔除不具备类药(Drug-Likeness)特征的分子,既能减少计算资源的消耗,又能提升最终筛选出的化合物质量。
4. 排除性质不良的化合物
配体库应避免纳入存在明确缺陷的化合物,例如应快速剔除“垃圾”化合物(REOS,Rapid Elimination of Swill)。REOS是药物发现中的一种计算过滤方法,它使用官能团规则(如反应基团、毒物载体)和属性过滤器从大型筛选库中快速剔除“不良的”化学结构(Swill),以便识别导致假阳性或类药性差的有问题的化合物,从而提高找到真正候选药物的效率。
此外,泛筛选干扰化合物(PAINS,Pan-Assay Interference Compounds)是药物发现中一类显示出非特异性和误导性活性的“捣乱分子”,它们可能通过化学反应、荧光干扰、蛋白质表面结合或形成胶体聚集等方式产生假阳性信号,浪费研究资源。
二、凸显化学空间的多样性与新颖性
充分利用骨架多样性,并探索丰富的化学型(chemotype),能够提高发现独特、新颖苗头化合物的概率。
在配体库中纳入多样化的化学类型,同时排除或搁置已申请专利的化合物,可打造出完全契合项目需求的专属化合物库。这种设计策略不仅能激发研发创新,还能最大程度降低潜在的法律或知识产权风险。
此外,若对目标靶点已具备一定的研究基础,围绕该靶点的已知活性化合物结构来设计配体库,也会是一种高效的策略。在化合物库中补充与靶点预期结合模式相匹配的分子,能够为研发提供战略优势,助力科研人员聚焦于最符合项目需求的化学空间区域。
三、构建高效配体库的推荐策略
无论是针对计算模拟筛选还是实验室筛选设计配体库,都应在保证化合物充分多样性的前提下,依据特定的理化性质进行筛选。研发团队需与药物化学家密切协作,明确筛选项目的核心目标,确保配体库的设计与靶点的属性特征高度契合。
对于库内的每一个配体化合物,都应具备这样的定位:一旦它被筛选为苗头化合物,研发人员就有能力对其开展后续研究。
采用严格的筛选标准并精心优化配体库,能够降低因非理想化合物带来的研发成本与挫败感。此外,在开展全规模计算模拟筛选前,可先选取部分配体进行预实验筛选,通过预实验结果进一步优化配体库。
尽管在筛选前无法百分百确保配体库的有效性,但遵循这些策略,能够大幅提升研发成功的概率,并为后续根据实际情况调整策略预留空间。
四、控制计算模拟筛选的成本
计算模拟筛选需要投入大量资源,包括计算资源、人力资源、数据分析成本以及软件授权费用。尽管相比传统的湿实验方法,计算模拟筛选的速度更快,但面对庞大的化学空间,其整体研发过程依然耗时且昂贵。
通过前瞻性的配体库设计与预实验筛选,能够有效减少对非理想化合物的后续处理流程,从而显著降低研发成本。
五、高效配体库设计的核心
计算模拟筛选流程的有效性,在很大程度上取决于所使用的化合物库质量。即便采用最精准的计算模型,若所选配体与项目目标不匹配,筛选工作也难以取得理想成效。例如,对于需要小分子化合物的中枢神经系统(CNS)药物研发项目,就不建议使用类肽化合物库。
从可靠的供应商处采购商业化化合物库,往往能为研发工作奠定坚实的基础。不过,后续仍需通过进一步的筛选与预实验,确保库内化合物与项目需求的相关性。
Schrödinger(薛定谔软件)已与Enamine、MilliporeSigma、MolPort、药明康德(WuXi)及Mcule达成合作,提供涵盖片段分子、类先导化合物、类药物前体及类药物分子的化合物数据库,化合物数量从数百万到数十亿不等,覆盖广阔的化学空间。这些库可以直接对接各类基于结构和基于配体的虚拟筛选技术(如下图)。
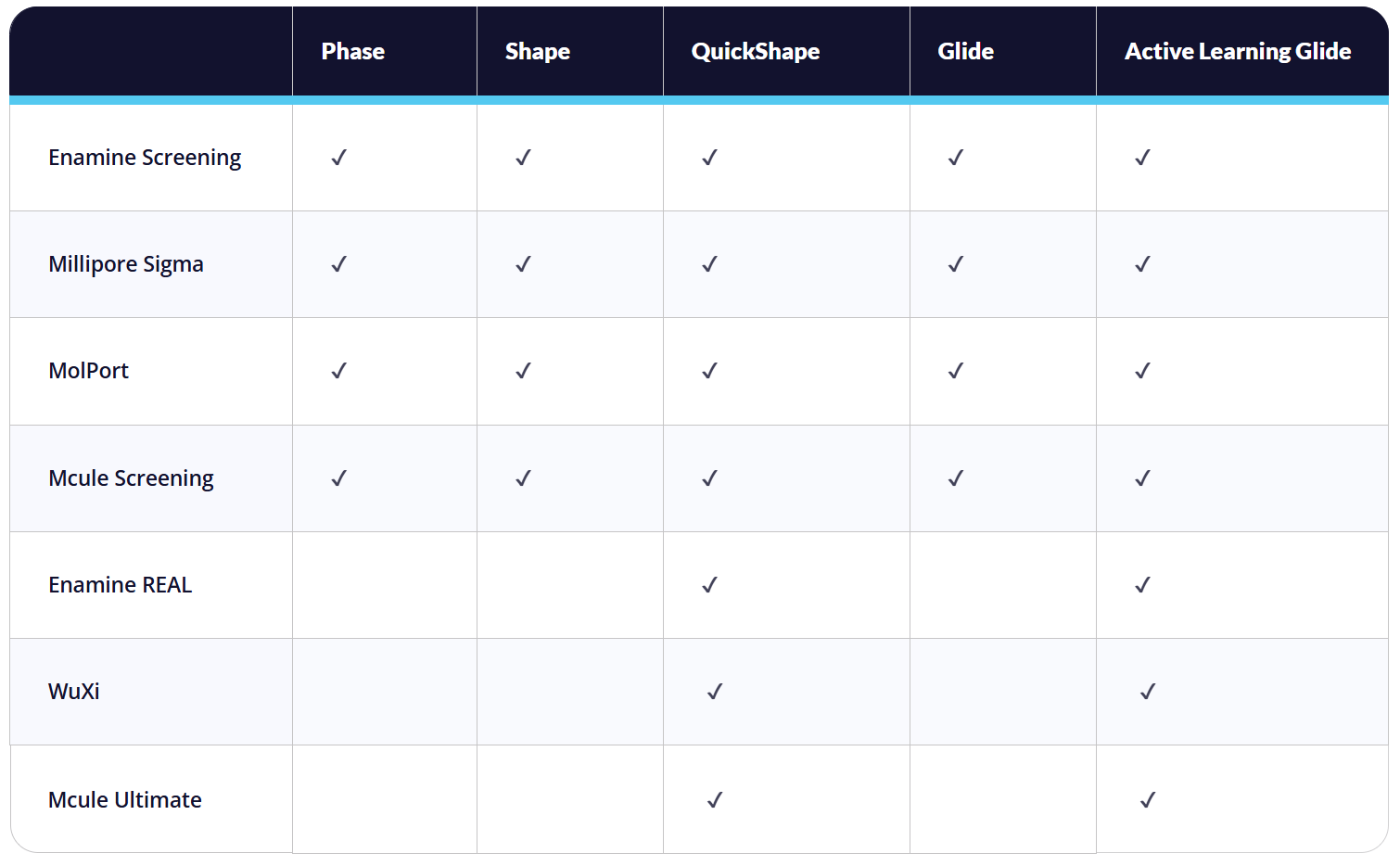
图注:薛定谔平台多样化的筛选技术和数据库
总之,一个高质量的配体库,能够通过减少时间与资源的投入,大大提升筛选项目的研发效率。精心的设计不仅能提高发现潜力苗头化合物的概率,还能降低因非理想化合物带来的研发风险。
欢迎联系我们获取薛定谔小分子数据库详情!
参考资料:
Elevate Your Screening Campaign: Designing Quality Ligand Libraries for Hit Discovery, Nov 14, 2025, Extrapolations


