

AI-enriched COMPUTATIONAL SIMULATION
AI计算模拟
以AI、大数据分析及数字化工作流为基础的综合计算模拟解决方案
主要特征
相互联系的报告连结转录因子,转录因子实验表征的结合位点和受调控的基因,以及启动子报告(含有映射注释的转录因子结合位点和高通量数据ChIP-seq等) 。
70,000多个转录因子结合位点报告,其中包括300多个物种的原始文献详细信息,主要关注的物种是人类、小鼠、大鼠、酵母和植物。
23,000多个转录因子(1,200 miRNA) 报告,提供GO功能、相关的疾病和表达模式信息。
提供67,000多个手动注释的转录因子 — 位点相互作用; 以及57,000多个miRNA-靶标位点相互作用的信息。
2,000多个包含27M转录因子结合片段/间隔的高通量TFBS ChIP实验报告,其中许多被注释为具有优质得分结合位点和邻近基因,以及161 DNase超敏性ChIP-Seq实验,包含15M片段和 1M组蛋白修饰片段。
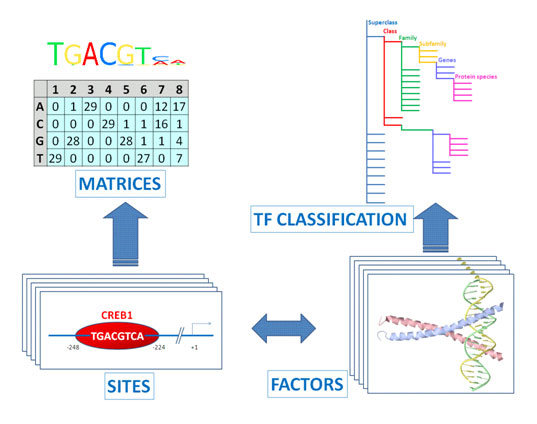
7,000多个结合位置权重矩阵被用在MatchTM,FMatch,CMsearch和部分geneXplain模块中来预测转录因子结合位点。
超过360,000个的启动子报告,涵盖了人类和9个其他物种,其中包括转录起始位点,CpG岛,单核苷酸多态性(SNP)和其他注释。
包括用于转录因子结合位点预测,从头基序识别,基质比较和miRNA调控子识别的工具。
此外,还包括一种通路可视化工具,用于构建定制已被实验证明的因子-DNA和因子–因子相互作用的调控网络,以及一个功能分析工具用于鉴别在分析的基因集中的共享属性。
结构
TRANSFAC数据库的核心内容是真核转录因子和转录因子结合位点。结合位点是一个转录因子结合位置权重矩阵(Positional Weight Matrices, PWM),PWM反映每个核苷酸在已知和已比对的TFBS上被发现的频率,即每个位置的碱偏好性。TRANSFAC数据库根据转录因子的DNA结合域属性,将转录因子分类。
应用
TRANSFAC数据库常用于预测可能性转录因子结合位点,也可以用于训练用户自己的模式,发现新算法,或者挖掘转录因子信息。
位点和启动子分析
使用TRANSFAC数据库的位置权重矩阵库,配合标准版TRANSFAC数据库自带的Match工具或选择geneXplain平台提供的相应工具,您能够分析出DNA序列的可能转录因子结合位点。


